a) Les differents type d'IA
Il existe différents type d'intelligences artificielles, elles sont différentes par leurs manière de fonctionner et donc leurs capacités à répondre à des taches précises.
- L'IA faible , l'IA faible ne cherche pas à reproduire l'intelligence humaine dans son intégralité :
Elle peut être modélisé par un système expert ( ce sont des logiciels qui cherchent à simuler la pensée d'un expert ).
Un système expert est composé de 3 parties:
- -Une base de fait
- -Une base de règle
- -Un moteur d'interférence
Les système experts sont donc capables de résoudre des problèmes. La Base de règles rassemble de nombreuses connaissances sur un thème précis. Les règles fonctionnent sur le principe de raisonnement logique:
Si X (fait ou prémisse) ALORS Y (Conclusion)
Exemple: SI un animal a 6 pattes, ALORS c'est un insecte.Le système expert fonctionne donc ainsi. Si le fait (ou prémisse) respecte une règle, alors une conclusion est donnée. Il faut donc respecter la cohérence des règles, pour éviter les incohérences. Les faits et les règles sont mis en relation par le moteur d'inférence, fonctionnant selon 3 chaînages, c'est à dire 3 raisonnements:
- Le chaînage avant applique les règles à partir des faits et en déduit de nouvelles conclusions
- Le chaînage arrière consiste à vérifier les hypothèses en partant de l'objectif
- Le chaînage mixte utilise les 2 précédents chaînages.
Les systèmes experts sont utilisés dans le monde de l'entreprise, pour résoudre des problèmes et aider à prendre des décisions. Ils ont aussi leur place dans le domaine de la médecine, et aident les médecins dans leurs choix.

Néanmoins, la connaissance du corps humains n'est pas complète, ce qui limite l'utilisation des systèmes experts dans ce domaine.
- Ce concept d'IA faible est confronté à l'IA forte, ayant de plus grandes ambitions. Son but est alors de se rapprocher un maxium du fonctionnement de l'intelligence humaine (car c'est, tout du moins pour l'instant,
l'intelligence la plus performante et surtout la plus polyvalente.) En effet, l'IA Forte est associé aux robots, dotés d'une grande autonomie, parfois totale. L'IA forte vise à donner à une machine comportement très proche de celui d'un humain confronté à la même situation, mais aussi une forme de "conscience", de "compréhension de ses propres raisonnements" ( Dictionnaire de l'informatique 1975, André le Garff).
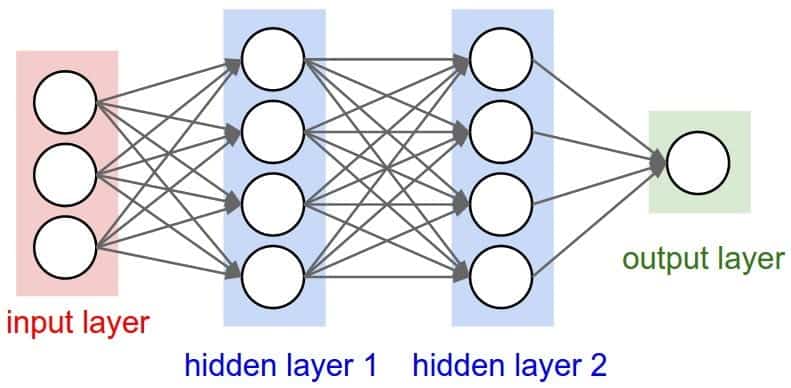
Une des formes de l'IA forte sont les réseaux de neurones. Comme leur nom l'indique, les réseaux de neurones visent à copier au mieux le fonctionnements de neurones biologiques tels que ceux des humains ou encore de certains animaux.
Les réseaux de neurones artificiels sont composés de neurones formels, la représentation mathématique d'un neurone biologique. Les neurones formels sont inventés en 1943 par Warren McCulloch et Walter Pitts. Dans ce modèle, chaque entrée reçue par le neurone formel est associé à un poids : w. Cette grandeur Σ est ensuite transformée par une fonction d'activation φ , ce qui permet d'obtenir une valeur finale à la sortie du neurone.
En 1949, Donald Hebb crée une règle permettant de doter les neurones formels d'un système d'apprentissage, et donc d'une mémoire. L'apprentissage Hebbien est décrit dans son ouvrage The organization of Behavior, paru en 1949
"When an axon of cell A is near enough to excite B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased" (The Organization of Behavior) Cette phrase explique le principe du synapse de Hebb, permettant l'apprentissage. Les synapses sont les zones de contacts entre deux neurones, permettant leur connexion. Selon cette règle, lorsque deux neurones connectés par un synapse sont activés simultanément, la force du synapse augmente. Ainsi, l'activation de l'un par l'autre sera simplifiée à l'avenir, grâce à ces connexions renforcées.
Comparaison d'un neurone biologique et d'un neurone artificiel, issu d'un document de Claude TOUZET en Juillet 1992.
L'IA forte est associée à la robotique, et donc aux robots : "Appareil effectuant, grâce à un système de commande automatique à base de micro-processeur, une tâche précise pour laquelle il a été conçu dans le domaine industriel, scientifique ou domestique" (définition de l'ATILF). Les robots dotés d'une IA forte et de réseaux de neurones artificiels seraient donc capables, en plus d'avoir un cerveau proche de celui des humains, de "s'auto-programmer". Elle auraient donc la capacité de s'adapter à des situations, et d'évoluer grâce à un système d'apprentissage. Ce programme générateur est appelé "IA germe" par Serge Boisse, chercheur français. La création d'un tel type d'Intelligence artificielle est complexe. Tout d'abord, le nombre de lignes de programme est énorme, estimé à plusieurs centaines de millions. Une des formes de la conception d'une IA forte serait un rassemblement de plusieurs "boîtes", correspondant aux différents niveaux du fonctionnement de l'esprit (concept, pensée, délibération, buts et conscience globale...), qui correspondent donc aux réseaux de neurones artificiels, programmés dans un but précis. Ces "boîtes" pourraient être décomposées en sous-systèmes, destinés à résoudre un problème en particulier. Ce concept d'IA germe pourrait aider à créer une IA forte, concept qui semble impossible de nos jours. Néanmoins, la création d'une IA forte, et donc d'un robot capable de pensée, de réflexion émet de nombreux problèmes:
- La conscience serait le propre des organismes vivants, et ne pourrait pas être donnée à une machine
- La pensée ne serait pas un phénomène calculable.
De plus, une machine dotée de la capacité de penser pourrait être difficile à contrôler par les humains. Serge Boisse et Eliezer Yudkowsk estiment qu'une IA germe "jeune" aurait une compréhension du monde semblable à un enfant de 6 ans, quelques mois plus tard celle d'un adulte et deviendrait quelques heures plus tard la première super-intelligence.
Le concept d'IA forte est donc encore à l'état de recherche de nos jours, aucune machine n'est encore capable d'avoir une intelligence semblable à l'intelligence humaine. Les idées concernant l'IA germe et le système d'apprentissage, d'auto-programmation est donc une représentation de l'IA forte à étudier.